Fully Managed
Omeka S
as a Service
Deploy Omeka S as a fully managed service starting at €9/mo. Get automated backups, SSL, updates, support and monitoring included.
Omeka S is a Linked Open Data publishing platform for libraries, archives, museums, and digital humanities teams — multi-site, IIIF-ready, RDF-native. It is the natural home for collections that need to publish as discoverable open data, not pile up behind a paywalled SaaS. We run the infrastructure underneath so curators and metadata staff can focus on the items.
✓Free 7-day trial ✓99.9% Uptime SLA ✓No credit card ✓Cancel anytime
✓Free 7-day trial ✓99.9% Uptime SLA
✓No credit card ✓Cancel anytime

Omeka S
STARTING AT
USAGE
 Germany
Germany Finland
Finland Netherlands
Netherlands UK
UK Sweden
Sweden United States
United States Canada
Canada Singapore
Singapore Japan
Japan Australia
Australia Brazil
Brazil South Africa+9 more →
South Africa+9 more →
ABOUT THE SOFTWARE
What is Omeka S
FEATURES
What Omeka S does
WHAT'S ALWAYS INCLUDED
Every app. Fully managed.
Nothing extra to pay for.
Every app you deploy includes the full managed service — security, backups, updates, and support from day one.
WHY MANAGED
Why teams pick managed Omeka S
REVIEWS
Hear from customers like you

No more maintenance headaches!
Finaly, I can relax and not bother with maintenance. Each of the softwares that we run on DANIAN is automated and running stable for couple months already. They even assist us with modifying the DNS records. Once we needed to modify the config of Nextcloud so that we are able to upload higher than 5GB files and they assisted us fast. I also love their documentation!

Kevin Blackwell

Best managed service
I previously ran Peertube, Mastodon, Mattermost and Mirotalk on other providers before switching to DANIAN. I was tired of handling the updates and backups myself. Not only that the performance is "out of this world" fast, but their tech support is amazing. Since then I added 5-10 more Apps on my account. I also love how they add more softwares on their list constantly!

William Northfield

Love the personalized service!

George Adams
n8n runs excellent

David Hartmann

Smooth experience
I needed a way to manage the projects and files for my company. This was the first time I learn about opensource. I asked their support and livechat and they assisted me immediately. I started with Openproject. Later I added Nextcloud. My team were able to get used to the apps fast.

Levi Nilsson

Bye GA

Wyatt Mitchell

Love the freedom
I wanted to use a crm for my startup. I signed up for the free trial. Tried out espocrm and dolibar and picked one. Their dashboard is very easy for a beginner. I recommend them and feel confident in choosing them.
Elias Koch
Wow just wow
After discovering DANIAN, I wished I'd found them sooner — their solution is excellent and deserves wider recognition. Very good solution!

Tyler Hollander
Professional tech support!

Bastian Engel
Their support team is the best!
I had a problem with my card and the subscription could not be renewed in time. I notified their support and surprisingly, they showed much understanding. They basically left my apps run until I solved the card issue. Other providers would have deleted my data in a heartbeat. This is the way to build client-vendor trust!
George Adams
Fair price and fast
4 months ago I activated n8n, Uptime kuma, Vaultwarden and Paperlessngx. So far everything is perfect. The performance of all apps is excellent. I contacted their support team couple times for using custom subdomains for the apps and they were fast and kind. I'm constantly recommending them to my network!

Atanas

Vaultwarden 10/10
I wanted to selfhost a passwords manager for my company but I didn't trust the mainstream providers. I tried out Vaultwarden for the free trial. I loved how their support team communicated with me professionally but still kind. I know that I can contact them whenever with whatever question I have. Recommended!

James Smith
Multiple locations options

Edward Nelson
Everything just works!
My focus is on my business, not running servers. I love that I can lauch any app without having to think about the tech behind it. Everything just works!
Tony Roy
Awesome support team!

Filip

Very proactive!
Today couple of the videos on my Peertube got viral. Before I even noticed, their support have notified me via email that they proactively upgraded my app with more cpu & ram so that it continues to work without any downtime. They left the upgraded app with the added resources for couple days until the traffic stabilizes. After that I had the possiblity to stay on the same plan or keep the upgraded plan. Out of gratitude I stayed on the upgraded one.

Luke Hall

Win-win!
I run a web design biz. After I perform the work for my clients, they constantly ask me for more software solutions. So I partnered with DANIAN. Not only I provide the requested softwares for my clients and get the increased revenue boost by delegating all to DANIAN, but also for those clients that wish to order directly from DANIAN, I send them an affiliate link. Win-win on all sides!

Luke Walker

Jeffrey Johnson
Awesome customer service
I needed to add analytics on my website but I didn't know anything about DNS. Their team guided me at all phases and they performed the changes for me. Additionally they were transparent and notified me of every change applied and steps performed.

Gabriele Marino

Good admin dashboard
Not only that I got Chatwoot, I also have access to the management dashboard. I love that I can view my hourly/daily usage and perform manual backups and restorations if needed. I don't need the level of control but it feels good to know that I have it if I need it.

Matthew Turner

Andreas Schmitt
Great service!
I configure custom Matomo tracking for my clients as a monthly service. Many of my clients were asking if they can selfhost Matomo instead of using the Cloud service. My employee recommended DANIAN. Basically, I can activate as much Matomo's in any of 20+ countries the same day. Additionally the affiliate revenue is a nice bonus.

Jacob Turner
Smooth experience
I was listing through youtube tuts on how to install Bookstack myself. Then randomly, I found their video playlist exactly for Bookstack. Got curious and went at their website. For the same price (or higher) that I would pay for just the VPS, with them I'm getting a fully managed Bookstack. It's a no-brainer decision!

Elias Gustafsson


Mason Hayes
Its a great service
Its a great service. I love the performance of my Mastodon community. It keeps on growing and I don't have any worries about backups, secuirity, updates, etc.

Vinícius Rocha

Very intuitive solution!
I wanted to use a nocode software for my company. A friend recommended them so I tried both Baserow and NocoDB, couple days later picked one.

Haruto Hashimoto


Henrik Otto
USE CASES
Three teams who run Omeka S on DANIAN
Three patterns we see most often: the university library running multiple curated exhibits on one shared item pool, the digital humanities project publishing Linked Open Data with maps and timelines, and the volunteer-run community archive on a small budget. The configuration choices below come from production installs.
UNIVERSITY LIBRARY · DIGITAL SCHOLARSHIP
Eleven curated exhibits on one shared item pool
A mountain-west research library runs eleven public Omeka S sites — including a digital pandemic archive, a Japanese-American memorial collection, and a regional religious history project — from a single install in a US region. Universal Viewer for IIIF, custom institutional theme, Dublin Core plus MODS metadata. Editor team of six. Solr-backed search across the full pool.
DIGITAL HUMANITIES RESEARCH · MADRID
Twenty historical maps, four thousand places, ten thousand cultural objects
A Spanish university digital humanities centre publishes a multilingual interactive atlas combining twenty historical maps of one city, four thousand places with timestamped history, and ten thousand cultural heritage objects pulled via IIIF from partner GLAM institutions. Runs in a Europe-Spain region. Modules: Custom Ontology, Geometry datatype, IIIF Server, Value Suggest. Four-researcher team.
Community archive · UNESCO heritage site
Six thousand items, volunteer-run, OAI-PMH-harvested
A UK community archive for a UNESCO World Heritage industrial site runs six thousand documents, photographs, maps, and objects on a volunteer cataloguing model. Modules: CSV Import, Faceted Browse, OAI-PMH Repository, Octopus Viewer for IIIF, Restricted Sites for in-progress collections. Two part-time paid staff, volunteer editors. Runs in a UK region.
COMPARISON
Four ways to run Omeka S
Most institutions evaluate three or four paths before settling on managed Omeka S. The proprietary library and archives platforms — ContentDM (OCLC) and Preservica — are the closest commercial peers. The self-host path is real but undercounts operator time. The fourth path is us. The math is below.
| PATH | STARTING (1 SITE, ≤5K ITEMS) | GROWING (5 SITES, ≤25K ITEMS) | AT SCALE (10 SITES, ≤100K ITEMS, IIIF) |
|---|---|---|---|
| ContentDM (OCLC) — proprietary SaaS | ~$3,372/yr ongoing | + $10,000 one-time tier upgrade | + $30,000 one-time tier upgrade |
| $24/mo production-class VPS, self-managed | ~€100–280/mo effective (infra + ops time at sysadmin rates) | ~€150–400/mo (more time + DB tuning) | ~€300–600+/mo (Solr, Cantaloupe, IIIF traffic, on-call) |
| Synology DS923+ NAS at home | ~€210–450/mo (hardware amortised + electricity + business internet + off-site backup) | Not viable at this scale (no redundancy) | Not viable at this scale (no redundancy) |
| DANIAN Managed Omeka S | €9/month flat | €9/month flat | €9/month flat |
BY INDUSTRY
Omeka S for specific industries
Different institutional types put different demands on Omeka S. Academic libraries care about ArchivesSpace integration and OAI-PMH harvest. Archives need EAD finding aids and PREMIS preservation metadata. Museums prioritise IIIF tile serving and CIDOC-CRM. Digital humanities projects want clean Linked Open Data publication. Here is what we tune for each.
FAQ
Frequently asked questions
Everything teams ask before signing up — answered straight, without sales speak.
Three groups: technical setup, migration, and how DANIAN works as a service.
01
Technical and configuration
02
Migration and onboarding
03
Billing, support, and platform
DEPLOY IN YOUR REGION
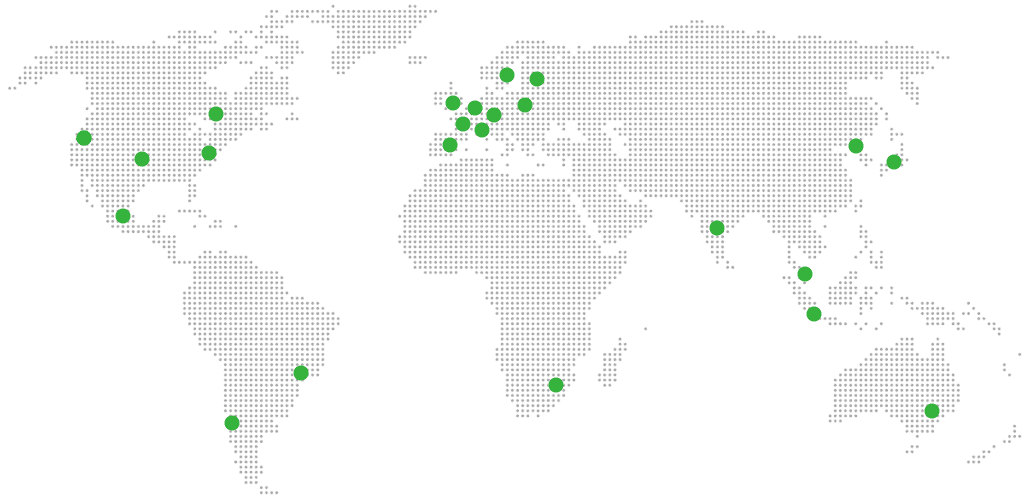
21 datacenter locations on six continents
Pick the region closest to your users.
United States, Germany, Finland, Singapore, Australia, Brazil, Canada, Netherlands, UK, Spain, Italy, France, Sweden, Malaysia, India, Japan, Mexico, Poland, South Korea, Chile, South Africa and more coming soon