Fully Managed
Uptime Kuma
as a Service
Deploy Uptime Kuma as a fully managed service starting at €9/mo. Get automated backups, SSL, updates, support and monitoring included.
Uptime Kuma is an open-source monitoring tool that watches HTTP endpoints, ports, certificates, databases, and push heartbeats from your own services. It produces public status pages and routes alerts through Slack, Discord, Telegram, email, and 90-plus other channels — combining the convenience of a hosted uptime monitor with the privacy and cost control of self-hosted infrastructure.
✓Free 7-day trial ✓99.9% Uptime SLA ✓No credit card ✓Cancel anytime
✓Free 7-day trial ✓99.9% Uptime SLA
✓No credit card ✓Cancel anytime

Uptime Kuma
STARTING AT
USAGE
 Germany
Germany Finland
Finland Netherlands
Netherlands UK
UK Sweden
Sweden United States
United States Canada
Canada Singapore
Singapore Japan
Japan Australia
Australia Brazil
Brazil South Africa+9 more →
South Africa+9 more →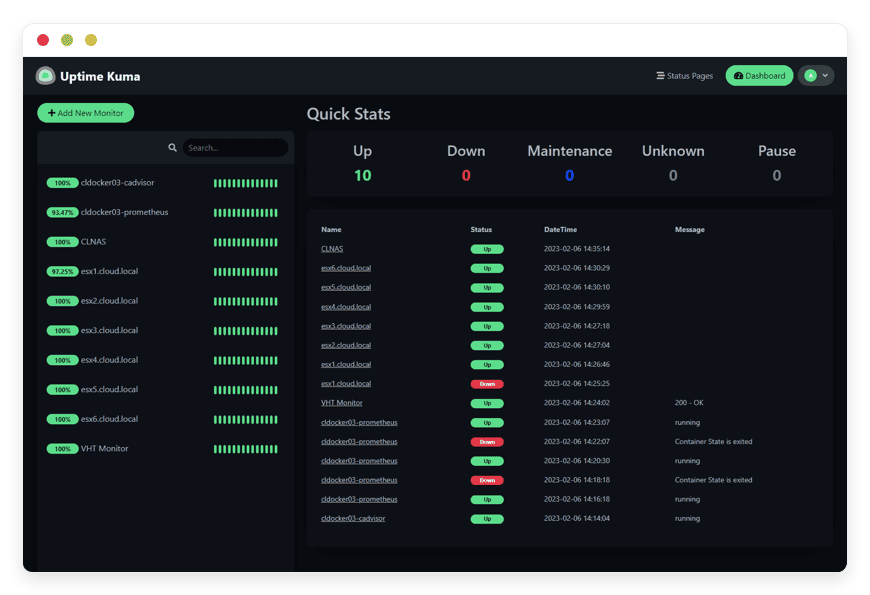
ABOUT THE SOFTWARE
What is Uptime Kuma
FEATURES
What Uptime Kuma does
WHAT'S ALWAYS INCLUDED
Every app. Fully managed.
Nothing extra to pay for.
Every app you deploy includes the full managed service — security, backups, updates, and support from day one.
WHY MANAGED
Why teams pick managed Uptime Kuma
REVIEWS
Hear from customers like you

No more maintenance headaches!
Finaly, I can relax and not bother with maintenance. Each of the softwares that we run on DANIAN is automated and running stable for couple months already. They even assist us with modifying the DNS records. Once we needed to modify the config of Nextcloud so that we are able to upload higher than 5GB files and they assisted us fast. I also love their documentation!

Kevin Blackwell

Best managed service
I previously ran Peertube, Mastodon, Mattermost and Mirotalk on other providers before switching to DANIAN. I was tired of handling the updates and backups myself. Not only that the performance is "out of this world" fast, but their tech support is amazing. Since then I added 5-10 more Apps on my account. I also love how they add more softwares on their list constantly!

William Northfield

Love the personalized service!

George Adams
n8n runs excellent

David Hartmann

Smooth experience
I needed a way to manage the projects and files for my company. This was the first time I learn about opensource. I asked their support and livechat and they assisted me immediately. I started with Openproject. Later I added Nextcloud. My team were able to get used to the apps fast.

Levi Nilsson

Bye GA

Wyatt Mitchell

Love the freedom
I wanted to use a crm for my startup. I signed up for the free trial. Tried out espocrm and dolibar and picked one. Their dashboard is very easy for a beginner. I recommend them and feel confident in choosing them.
Elias Koch
Wow just wow
After discovering DANIAN, I wished I'd found them sooner — their solution is excellent and deserves wider recognition. Very good solution!

Tyler Hollander
Professional tech support!

Bastian Engel
Their support team is the best!
I had a problem with my card and the subscription could not be renewed in time. I notified their support and surprisingly, they showed much understanding. They basically left my apps run until I solved the card issue. Other providers would have deleted my data in a heartbeat. This is the way to build client-vendor trust!
George Adams
Fair price and fast
4 months ago I activated n8n, Uptime kuma, Vaultwarden and Paperlessngx. So far everything is perfect. The performance of all apps is excellent. I contacted their support team couple times for using custom subdomains for the apps and they were fast and kind. I'm constantly recommending them to my network!

Atanas

Vaultwarden 10/10
I wanted to selfhost a passwords manager for my company but I didn't trust the mainstream providers. I tried out Vaultwarden for the free trial. I loved how their support team communicated with me professionally but still kind. I know that I can contact them whenever with whatever question I have. Recommended!

James Smith
Multiple locations options

Edward Nelson
Everything just works!
My focus is on my business, not running servers. I love that I can lauch any app without having to think about the tech behind it. Everything just works!
Tony Roy
Awesome support team!

Filip

Very proactive!
Today couple of the videos on my Peertube got viral. Before I even noticed, their support have notified me via email that they proactively upgraded my app with more cpu & ram so that it continues to work without any downtime. They left the upgraded app with the added resources for couple days until the traffic stabilizes. After that I had the possiblity to stay on the same plan or keep the upgraded plan. Out of gratitude I stayed on the upgraded one.

Luke Hall

Win-win!
I run a web design biz. After I perform the work for my clients, they constantly ask me for more software solutions. So I partnered with DANIAN. Not only I provide the requested softwares for my clients and get the increased revenue boost by delegating all to DANIAN, but also for those clients that wish to order directly from DANIAN, I send them an affiliate link. Win-win on all sides!

Luke Walker

Jeffrey Johnson
Awesome customer service
I needed to add analytics on my website but I didn't know anything about DNS. Their team guided me at all phases and they performed the changes for me. Additionally they were transparent and notified me of every change applied and steps performed.

Gabriele Marino

Good admin dashboard
Not only that I got Chatwoot, I also have access to the management dashboard. I love that I can view my hourly/daily usage and perform manual backups and restorations if needed. I don't need the level of control but it feels good to know that I have it if I need it.

Matthew Turner

Andreas Schmitt
Great service!
I configure custom Matomo tracking for my clients as a monthly service. Many of my clients were asking if they can selfhost Matomo instead of using the Cloud service. My employee recommended DANIAN. Basically, I can activate as much Matomo's in any of 20+ countries the same day. Additionally the affiliate revenue is a nice bonus.

Jacob Turner
Smooth experience
I was listing through youtube tuts on how to install Bookstack myself. Then randomly, I found their video playlist exactly for Bookstack. Got curious and went at their website. For the same price (or higher) that I would pay for just the VPS, with them I'm getting a fully managed Bookstack. It's a no-brainer decision!

Elias Gustafsson


Mason Hayes
Its a great service
Its a great service. I love the performance of my Mastodon community. It keeps on growing and I don't have any worries about backups, secuirity, updates, etc.

Vinícius Rocha

Very intuitive solution!
I wanted to use a nocode software for my company. A friend recommended them so I tried both Baserow and NocoDB, couple days later picked one.

Haruto Hashimoto


Henrik Otto
USE CASES
Three teams who run Uptime Kuma on DANIAN
These are representative team types we set up most often. Each starts with the same flat €9 plan.
12-PERSON MANAGED-SERVICE PROVIDER
80 client endpoints, one dashboard, one chat channel
Runs Uptime Kuma in Germany with 180-day retention, and 80 monitors tagged by client. Each tag drives a private status page on a customer-domain reverse-proxy host rule. Slack routing splits tier-1 clients to #noc-critical and tier-3 to #noc-watch. Monthly client uptime reports email out via the platform SMTP relay.
5-PERSON B2B SAAS STARTUP
Production, staging, payment webhooks, all in one dashboard
Runs in Brazil on the base €9 instance. 28 monitors covering production API (HTTP keyword on /health), staging, marketing site, Stripe webhook receiver (push monitor every minute), and Postgres TCP on the app subnet. Public status page at status dot example dot com on a Cloudflare front. PagerDuty for P1, Discord for everything else.
FEDERATION COMMUNITY ADMIN
PeerTube, Mastodon, Matrix, and the .well-known endpoints they break on
Runs in Finland, 365-day retention for transparency reports. 22 monitors covering each Fediverse service's main port plus the /.well-known/host-meta and /.well-known/webfinger endpoints that federate independently. ntfy push notification to the admin's phone, public status page open to the community at status dot community dot tld.
COMPARISON
Four ways to run Uptime Kuma
Four common paths to running Uptime Kuma: pay UptimeRobot or another hosted monitor instead, rent a VPS and run it yourself, run it on a home or office server, or have DANIAN manage it for €9 per month. Costs and the trade-offs each path makes are below.
| PATH | 10 MONITORS | 100 MONITORS | 200 MONITORS | YOUR OPS TIME | NOTES |
|---|---|---|---|---|---|
| UptimeRobot (the hosted SaaS being replaced) | $9/mo Solo | $38/mo Team | $69/mo Enterprise | 0 hr/mo | 1-minute checks; 3 seats on Team; commercial use blocked on Free since 1 Dec 2024 |
| Self-host on a $24/mo production-class VPS | $44/mo infra | $44/mo infra | $44+/mo infra | 1–4 hr/mo | OS patching, TLS renewal, /app/data backup; |
| Home server (HP ProLiant ML30 Gen10, ~€800–1,500) | €85–187/mo | €85–187/mo | €85–187/mo | 2–4 hr/mo | Hardware amortised over 36 months, electricity, business internet with static IP, off-site backup target; no native multi-region probing |
| DANIAN Managed Uptime Kuma | €9/mo | €9/mo | €9/mo | 0 hr/mo | 90-day retention, nightly snapshots, SMTP relay, second-region meta-monitor, 24/7 chat, region of your choice across 21 datacenters |
BY INDUSTRY
Uptime Kuma for specific industries
Uptime monitoring lives in different operational contexts depending on industry. A managed-service provider's instance looks nothing like an e-commerce site's, and an agency monitoring 30 client WordPress sites needs different tagging than a SaaS startup monitoring its own three apps. Five industries with the configurations that fit them below.
FAQ
Frequently asked questions
Everything teams ask before signing up — answered straight, without sales speak.
Three groups: technical setup, migration, and how DANIAN works as a service.
01
Technical and configuration
02
Migration and onboarding
03
Billing, support, and platform
DEPLOY IN YOUR REGION
21 datacenter locations on six continents
Pick the region closest to your users.
United States, Germany, Finland, Singapore, Australia, Brazil, Canada, Netherlands, UK, Spain, Italy, France, Sweden, Malaysia, India, Japan, Mexico, Poland, South Korea, Chile, South Africa and more coming soon